
機械学習について本やサイトを見て勉強していると「転移学習」という言葉が出てきますよね。
実はこの転移学習が日々発展している機械学習の研究の中で人間の能力により近づくきっかけになるかもしれないと期待されています。
人間の能力に近づくかもと言われてもじゃあ今の生活に何か関係しているものがあるのかピンと来なかったり転移とだけ言われると医療関係の用語を連想してしまい結局何のことだかわからぬまま終わりがちなのも事実。
それではまず、そもそも転移学習とは何かからお伝えしていきます。
転移学習とは

まず、転移学習は学習済みモデルというある目的に沿ってあらかじめ学習したことを別の目的にも使うことで再び学習をする効率をあげること。
これだけだとちょっとわかりにくいので楽器の練習に置き換えます。
とある学生さんで高校時代までバンド活動をしギターを弾いていたとします。
その後サークルなどで三味線やシタールに転向してもギターの経験そのものが無駄になることはないですよね。
転移学習とファインチューニングの違い

転移学習は学習済みモデルを別の目的でも用いることと触れましたが学習済みモデルを使う機械学習の手法としてファインチューニングというものもあります。
どちらも別物ではあるものの混同されがちなのでどう違うのかここでクリアにしましょう。
重みはディープラーニングに欠かせないものの一つであるニューラルネットワークに入力する数値にどれが重要だったり結果に貢献しているかといった度合いを数値化したもの。
学習済みモデルの層が持つ元々の重み(初期値)に調整を加え再び学習させるのがファインチューニング。
転移学習のメリット・デメリット

ここまで転移学習とは何かやファインチューニングとの違いについて触れましたが本当にいいことばかりなのかスッキリしないですよね。
ここでは転移学習を利用するメリットとデメリットについて整理していきましょう。
転移学習のメリット
これは自動運転のような高度な技術開発の際に威力を発揮します。
元から品質の高いデータがたくさんある領域の知識を活用していけば限定的なデータ量を補っていくことが可能。
また、学習済みモデルの再利用という形を取るのでゼロから学習させる必要がなく時間短縮に繋げることもできます。
転移学習のデメリット
転移学習のデメリットとして挙げられるのはかえって精度が悪化してしまう場合もあること。
これを「負の転移」と言います。
原因として挙げられるのは転移させる方法が悪かったりそもそも転移元と転移先であまりにもかけ離れている場合。
転移学習が活用された例

転移学習を使えばデータ量が不足してても補っていける。
じゃあ実際に使われた例ってあるの?となりますよね。
その一つが新型コロナウィルス対策。
ここでは診断精度の向上に役立てた研究事例を紹介します。
この研究ではVGG16、ResNet50、DenseNet121、InceptionResNetV2という計4種類のCNNでそれぞれ事前に訓練したモデルに転移学習を利用、胸部X線画像とCT画像から患者のものかどうか差別化に繋がる有益な特徴を抽出しました。
非常に少ない枚数であるにも関わらず従来の手法より診断結果の精度が向上しており今後の更なる応用が期待されています。
簡単に転移学習を行ってみよう

事例について触れたので今度は実際に転移学習をやってみましょう。
今回はPythonのライブラリの一つであるKerasにて提供されているCIFAR-10という10種類の物体カラー写真のデータセットと画像認識で有名なモデルの一つであるVGG16を使用します。
世界レベルの精度で1000クラスを分類できるモデルを活用すれば10種類の分類など赤子の手を捻るように見えますよね。
それでは進めていきましょう。
今回はGoogle ColabからTensorFlowとKerasを使用します。
ライブラリとデータの読み込み
import tensorflow as tf from tensorflow import keras from tensorflow.keras.models import Model, Sequential from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D, GlobalAveragePooling2D from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.datasets import cifar10 from tensorflow.keras.applications import vgg16 as VGG16 from tensorflow.keras.optimizers import Adam from tensorflow.keras.utils import to_categorical from tensorflow.keras.preprocessing import image from tensorflow.keras.applications.xception import preprocess_input, decode_predictions from tensorflow.keras.callbacks import EarlyStopping #!pip install dlt 必要に応じ使用 import dlt import os import numpy as np import matplotlib.pyplot as plt #https://www.tensorflow.org/tutorials/images/classification?hl=ja print(tf.__version__)
2.0.0
data = dlt.cifar.load_cifar10()
# 画像の簡単な前処理
# ベクトル形式に変更
# RGB 255 = white, 0 = black
X_train = data.train_images.reshape([-1, 32, 32, 3])
X_test = data.test_images.reshape([-1, 32, 32, 3])
print('%i training samples' % X_train.shape[0])
print('%i test samples' % X_test.shape[0])
print(X_train.shape)
# RGBの数値(0-255)を(0-1)に変更
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# クラスのラベルをワンホットエンコーディングに変更
Y_train = to_categorical(data.train_labels, 10)
Y_test = to_categorical(data.test_labels, 10)
Downloading CIFAR-10 dataset 50000 training samples 10000 test samples (50000, 32, 32, 3)
今回のデータは
幅32×高さ32ピクセルで1つ分のデータが基本的に(3, 32, 32)もしくは(32, 32, 3)(=計3072要素)という多次元配列の形状となっています。
最初もしくは最後の次元にある3要素がRGB値。
訓練用データで50,000枚、テスト用は10,000枚揃えられています。
層の追加とネットワーク構造の固定
次に層を重ねていきます。
Xceptionという構造を使いすべての層を通過した後のモデルのインスタンスをbase_modelとして取り出します。
include_topというところをFalseにしないと転移学習ができなくなるので要注意です。
# ベースモデルの作成 base_model = keras.applications.vgg16.VGG16(include_top=False, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000) print(base_model.summary())
Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, None, None, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, None, None, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, None, None, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, None, None, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, None, None, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, None, None, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, None, None, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, None, None, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, None, None, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, None, None, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, None, None, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, None, None, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, None, None, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, None, None, 512) 0 ================================================================= Total params: 14,714,688 Trainable params: 14,714,688 Non-trainable params: 0 _________________________________________________________________ None
続けてネットワーク構造を固定。
for layer in base_model.layers:
layer.trainable = False
base_modelの後に追加された層はCIFAR-10の学習で影響を受けることで重みが更新されます。
x = base_model.output x = GlobalAveragePooling2D()(x) # 層を追加 x = Dense(1024, activation='relu')(x) # さらに層を追加 predictions = Dense(10, activation='softmax')(x) # 今回使用するモデルがこれ model = Model(inputs=base_model.input, outputs=predictions) print(model.summary())
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, None, None, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, None, None, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, None, None, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, None, None, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, None, None, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, None, None, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, None, None, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, None, None, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, None, None, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, None, None, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, None, None, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, None, None, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, None, None, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, None, None, 512) 0 _________________________________________________________________ global_average_pooling2d (Gl (None, 512) 0 _________________________________________________________________ dense (Dense) (None, 1024) 525312 _________________________________________________________________ dense_1 (Dense) (None, 10) 10250 ================================================================= Total params: 15,250,250 Trainable params: 535,562 Non-trainable params: 14,714,688 _________________________________________________________________ None
ネットワークの構造が決まったのでモデルをコンパイルし精度まで見ていきましょう。
print(model.summary())
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(lr=0.001),
metrics=['accuracy'])
es = EarlyStopping(monitor='val_loss', min_delta=0, patience=3, verbose=0, mode='auto')
fit = model.fit(X_train, Y_train,
batch_size=128,
epochs=40,
verbose=2,
validation_split=0.1,
callbacks=[es]
)
score = model.evaluate(X_test, Y_test,
verbose=0
)
print('Test score:', score[0])
print('Test accuracy:', score[1])
# 出力先の作成
folder = 'results'
if not os.path.exists(folder):
os.makedirs(folder)
model.save(os.path.join(folder, 'my_model_tl.h5'))
# モデルから予測
preds = model.predict(X_test)
cls = np.argmax(preds,axis=1)
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, None, None, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, None, None, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, None, None, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, None, None, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, None, None, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, None, None, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, None, None, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, None, None, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, None, None, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, None, None, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, None, None, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, None, None, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, None, None, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, None, None, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, None, None, 512) 0 _________________________________________________________________ global_average_pooling2d (Gl (None, 512) 0 _________________________________________________________________ dense (Dense) (None, 1024) 525312 _________________________________________________________________ dense_1 (Dense) (None, 10) 10250 ================================================================= Total params: 15,250,250 Trainable params: 535,562 Non-trainable params: 14,714,688 _________________________________________________________________ None Epoch 1/40 352/352 - 11s - loss: 1.3655 - accuracy: 0.5268 - val_loss: 1.2005 - val_accuracy: 0.5802 Epoch 2/40 352/352 - 6s - loss: 1.1691 - accuracy: 0.5927 - val_loss: 1.1421 - val_accuracy: 0.6006 Epoch 3/40 352/352 - 6s - loss: 1.0979 - accuracy: 0.6142 - val_loss: 1.1355 - val_accuracy: 0.6030 Epoch 4/40 352/352 - 6s - loss: 1.0444 - accuracy: 0.6326 - val_loss: 1.1082 - val_accuracy: 0.6154 Epoch 5/40 352/352 - 6s - loss: 0.9933 - accuracy: 0.6517 - val_loss: 1.0906 - val_accuracy: 0.6232 Epoch 6/40 352/352 - 6s - loss: 0.9449 - accuracy: 0.6703 - val_loss: 1.0706 - val_accuracy: 0.6254 Epoch 7/40 352/352 - 6s - loss: 0.9074 - accuracy: 0.6812 - val_loss: 1.0686 - val_accuracy: 0.6302 Epoch 8/40 352/352 - 6s - loss: 0.8696 - accuracy: 0.6958 - val_loss: 1.0744 - val_accuracy: 0.6374 Epoch 9/40 352/352 - 6s - loss: 0.8309 - accuracy: 0.7080 - val_loss: 1.0820 - val_accuracy: 0.6276 Epoch 10/40 352/352 - 6s - loss: 0.7856 - accuracy: 0.7262 - val_loss: 1.0713 - val_accuracy: 0.6360 Test score: 1.0986547470092773 Test accuracy: 0.6241999864578247
# 精度を可視化
for i in range(10):
dlt.utils.plot_prediction(
preds[i],
data.test_images[i],
data.test_labels[i],
data.classes,
fname=os.path.join(folder, 'test-%i.png' % i))
plt.plot(fit.history['accuracy'])
plt.plot(fit.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.grid()
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
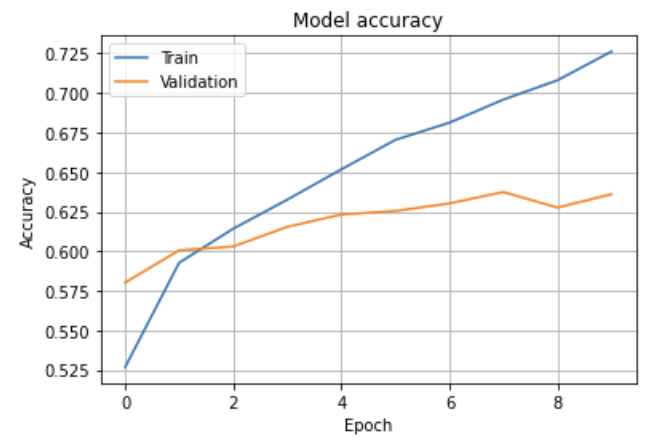
精度は上のように変わっていきました。
より精度を上げていく方法の一つとしてファインチューニングをしハイパーパラメータを調整するというのが挙げられます。
実際に転移学習を行う際の注意点

簡単に転移学習を行ってみましたが本格的にやっていく際に注意すべき点があります。
それはデメリットとして言及した「負の転移」が起きないようにすること。
転移元と転移先で扱っているものや目的で大きく逸れないようにするのはもちろん、転移元で学習してきたことが新しい学習の妨げになってないかにも注意が必要です。

今回は転移学習とは何かからスタートしファインチューニングとの違い、メリットとデメリットについて触れつつ簡単な実装をし最後に注意点の確認をしました。
転移学習は学習済みモデルというある目的に沿ってあらかじめ学習したことを別の目的にも使うこと。
新しい目的のためにゼロからデータを集める負担や学習にかかる時間を軽くすることができます。
学習済みモデルの層が持つ元々の重みをいじるかがファインチューニングとの違いで転移学習ではノータッチ。
転移学習は新型コロナ対策でも活用が進められており今後の活躍に期待していきましょう。
【お知らせ】
当メディア(AIZINE)を運営しているAI(人工知能)/DX(デジタルトランスフォーメーション)開発会社お多福ラボでは「福をふりまく」をミッションに、スピード、提案内容、価格、全てにおいて期待を上回り、徹底的な顧客志向で小規模から大規模ソリューションまで幅広く対応しています。
御社の悩みを強みに変える仕組みづくりのお手伝いを致しますので、ぜひご相談ください。
![お多福ラボコーポレートサイトへのバナー]()

