
機械学習の入門書などを読んでいると度々見かけるk-means。
本を読み進めていくとk-meansの他にk近傍法などkがつく用語が度々出てきて紛らわしいですよね。
直接AI(人工知能)を実装するエンジニアでなくてもこれを使えるだけで手元にあるデータからできることの幅を増やしていくことができます。
今回使用するのは新型コロナ対策をめぐるオープンデータ。
これを機に新聞やテレビなどと違ったアプローチから情報を得られるようにもしていきましょう。
それではまず、そもそもクラスタリングとは何かというところからお伝えします。
まずはクラスタリングとは

クラスタリングは与えられたデータの中から似たもの同士の集まり(=クラスタ)を作っていく手法。
機械学習の中では教師なし学習にあたります。
身近な事例としてあげられるのはECサイト。
階層的クラスタリングと非階層的クラスタリングの違い

似たもの同士を集めるクラスタリングですが「階層的クラスタリング」と「非階層的クラスタリング」のふたパターンがあります。
両者の違いは分割するクラスタの数をあらかじめ決めるかどうか。
事前に決めるのは非階層的クラスタリングの方となります。
データ同士で似たもの同士からまとめていく場合と逆に似てないもの同士で距離を取らせるといった方法があります。
この手法であれば最終的な結果を樹形図を使って可視化することも可能です。
k-meansのアルゴリズム

ここまでクラスタリングとは何か、階層的クラスタリングと非階層的クラスタリングの違いについて触れていきました。
k-meansという名前にあるkはクラスタの数で実装の際に具体的な数字を決めていくことになります。
k-meansのアルゴリズムで代表的な手順は以下の通り。
- まず、最初のステップとしてデータの点からクラスタの数だけ適当な点を選択しそれらを重心とします。
- 次にデータ点が重心とどれくらい離れているかを計算、距離が一番小さい重心のクラスタに所属することとなります。
- 一通りクラスタが完成したらそれぞれに所属するデータ点の平均値を新たな重心として扱います。
ここまでの流れでとりわけ大事なのがクラスタ作りと新たな重心の選定。
k-meansのメリットデメリット

やっていることは決められたクラスタ作りと新たな重心の選定を繰り返しで実装する側がやるのはクラスタの数を決めるだけ。
単純であるおかげで計算負荷も小さいのでビジネスの場で膨大なデータを扱うことがあっても手早く計算させることができます。
先程紹介したアルゴリズムの手順を振り返りましょう。
最初のステップとしてデータの点からクラスタの数だけ適当な点を選びそれらを重心とする、それを基にクラスタ作りや重心の選定へ繋げることとなります。
最初のクラスタがどう割り振られるかによって同じ条件でもその時々で全然違ったものになる場合も少なくありません。
k-meansをPythonで実装してみよう

最後にk-meansを実際に動かしてみましょう。
今回はAnacondaよりJupyterLabを使用します。
ここでは新型コロナウィルス対策として自治体ごとのワクチン接種の進捗状況をクラスタ化します。
データは政府CIOポータルがオープンデータで配布している「都道府県別累積接種回数サマリー」を使用します。
まず、オープンデータと同じフォルダでJupyterLabを起動、使用するライブラリを読み込んでください。
import pandas as pd import matplotlib.pyplot as plt %matplotlib inline from sklearn.cluster import KMeans
ライブラリを読み込んだのでオープンデータを読み込んでいきます。
df = pd.read_csv("summary_by_prefecture.csv", encoding="shift-jis")
# 文字コードエラー回避のためshift-jisを使用しています
df.head()
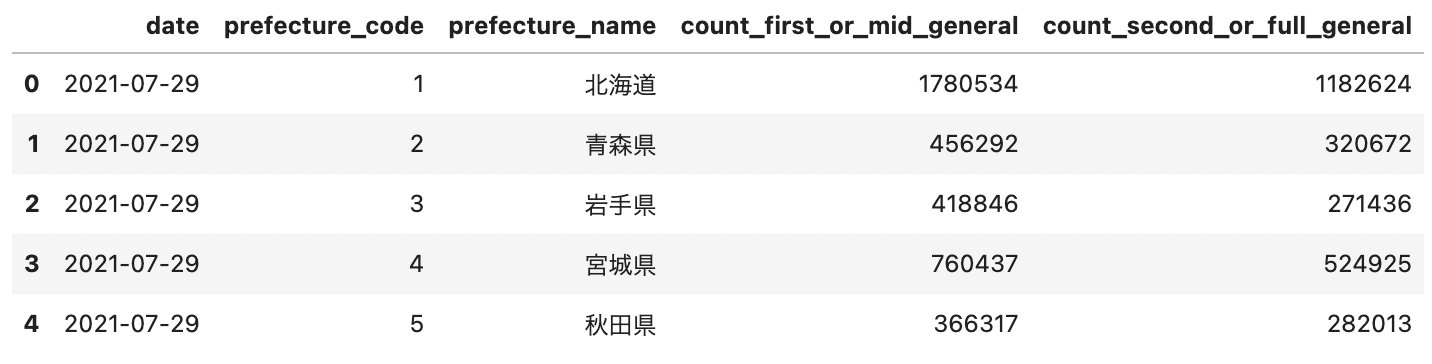
df.dtypes
date object prefecture_code int64 prefecture_name object count_first_or_mid_general int64 count_second_or_full_general int64 dtype: object
df.isnull().sum()
date 0 prefecture_code 0 prefecture_name 0 count_first_or_mid_general 0 count_second_or_full_general 0 dtype: int64
これで2021年7月29日時点での都道府県別累積接種回数のデータを読み込むことができました。
ここでは1回目の接種回数、その中で2回目がまだの件数の分布を可視化します。
df["wait_for_second"] = df["count_first_or_mid_general"] - df["count_second_or_full_general"] X = df[["count_first_or_mid_general", "wait_for_second"]]
plt.figure(figsize=(12,8))
plt.scatter(X["count_first_or_mid_general"], X["wait_for_second"],marker="o", facecolor="none",
edgecolors="black", s=80)
x_min, x_max = X["count_first_or_mid_general"].min(), X["count_first_or_mid_general"].max()
y_min, y_max = X["wait_for_second"].min(), X["wait_for_second"].max()
plt.title("Vaccin First and Waiting for Second")
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.show()
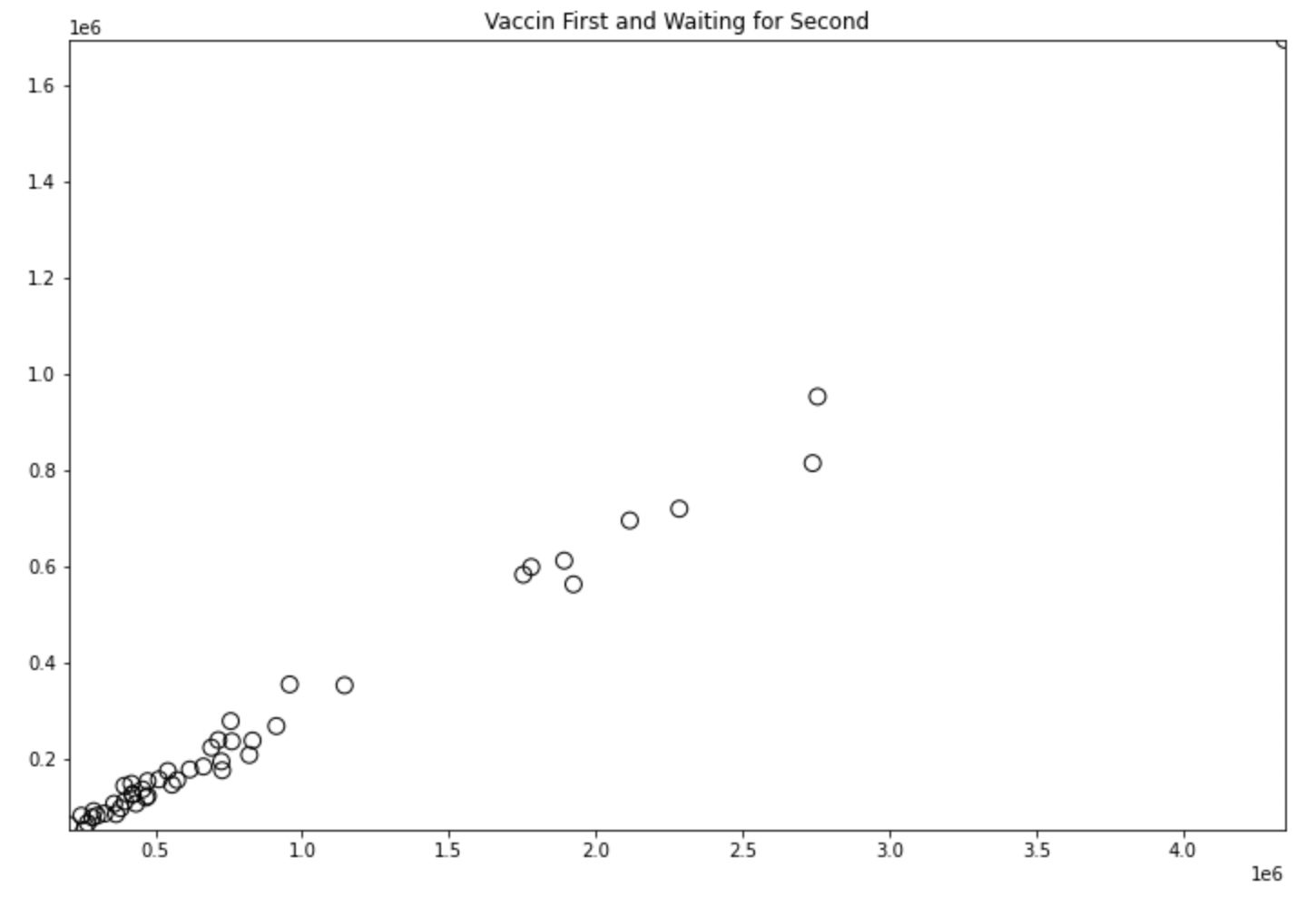
このグラフの横軸は接種1回目の回数、縦軸がそれに対し2回目の接種回数を引いたもので1e6は100万のことを指します。
ぱっと見で1回目接種が150万回未満、150万回以上250万回未満、250万回以上の3つで固まっているような印象。
なのでクラスタ数を3としてk-meansを動かしていきます。
kmeans = KMeans(n_clusters=3,n_init=10) #クラスタ数は3、アルゴリズムを10回実行
result = kmeans.fit(X)
k-meansのモデルを訓練できたので出力の推定を行います。
output = kmeans.predict(X)
plt.scatter(X["count_first_or_mid_general"], X["wait_for_second"], c=result.labels_) plt.show()
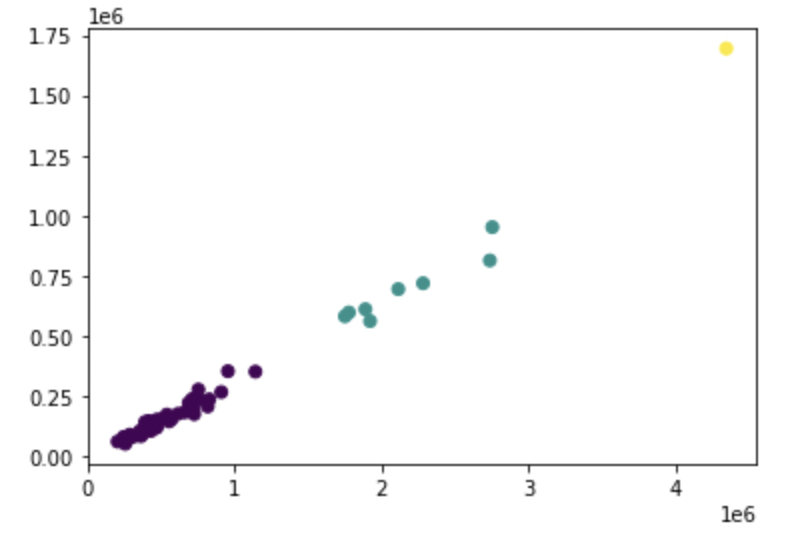
当初想定していた150万回以上250万回未満と250万回以上はほぼ同じクラスタで400万回を超えている自治体一件のみが独立したものとして扱われているようです。
df[df["count_first_or_mid_general"] > 4000000]["prefecture_name"]
12 東京都 Name: prefecture_name, dtype: object
東京都の接種回数は他と比べても多くその分2回目の接種を待つ人も少ないということがわかりました。
ここでは人口に対する接種率までは入れていないのでまた違った視点からの分析していくことも可能です。

今回はクラスタリングの代表的な手法の一つであるk-meansにフォーカスを当てそもそもクラスタリングとは何かというところからPythonでの実装まで解説していきました。
クラスタリングは与えられたデータの中から似たもの同士の集まり(=クラスタ)を作っていく手法で教師なし学習にあたります。
指定したクラスタ数の基でクラスタ作りと新たな重心の選定を繰り返していきます。
k-meansはPythonと手持ちのデータがあれば手軽に分析していくこともできます。
このご時世だからこそ怪しい情報に惑わされず一次情報をうまく活用するきっかけにできるといいですよね。
今回のコードはGitHubでも公開しているので参考にしてください。
