
AI(機械学習)の技術的な内容を扱う書籍や専門的な記事を読んでいると、「学習不足」や「未学習」「underfitting」という言葉を見かけることがありますよね。これらは機械学習に興味を持って勉強している人でなければ、あまり聞きなれない言葉だと思われる方が多いかもしれません。
そこで今回は、「学習不足」「未学習」「underfitting」とは何か?についてお伝えします。
一言で言うと「学習不足(未学習、underfitting)」とは・・・
学習不足とは、モデルに柔軟性が無い状態
「学習不足」の意味を理解するには、まず機械学習の基本的な部分から理解からしていく必要があります。
機械学習とは、AI(人工知能)を実現するための技術の一つで現在世間から非常に注目を集めています。そして機械学習をさらに詳しく説明すると、コンピュータがデータからデータに潜むパターンや傾向を見つけ出して(モデルの構築)、その結果を元に未知のデータに対して予測を行なっていくというものです。この、データに潜むパターンや傾向を数式で表現したものを「モデル」と呼びます。
機械学習のイメージとして例えば、次のようにデータがあった場合に、、
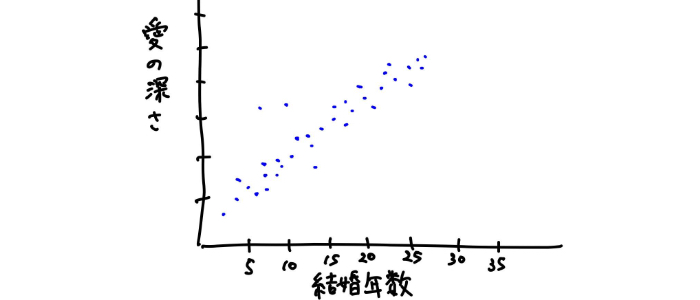
このようにデータの傾向やパターンを表現する直線が引けそうですよね。
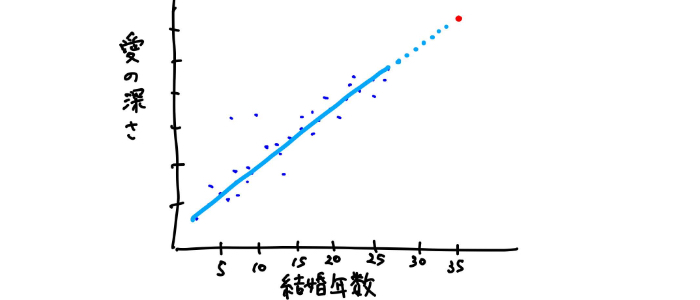
この直線を引くこと(数式を求める)ことが、モデルの構築です。改めて、このデータの傾向やパターンを表現している線がモデルなのですが、このように適切に線(モデル)を引くためには、モデルにデータを与えてあげる必要があります。なぜならデータがなければデータの傾向を掴んでいくことができないからです。
そして、モデルを学習させるために使うデータは一般的に「訓練(学習)データ」と言れますが、一方で訓練データとは別にモデルが未知のデータに対しても予測できるのかを確認するための「テストデータ」があります。
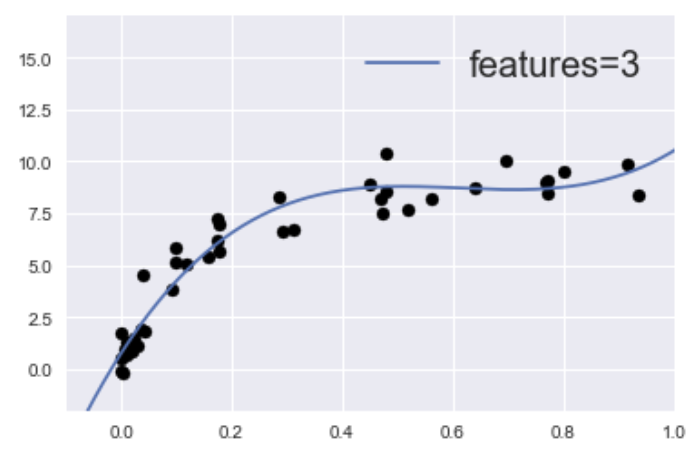
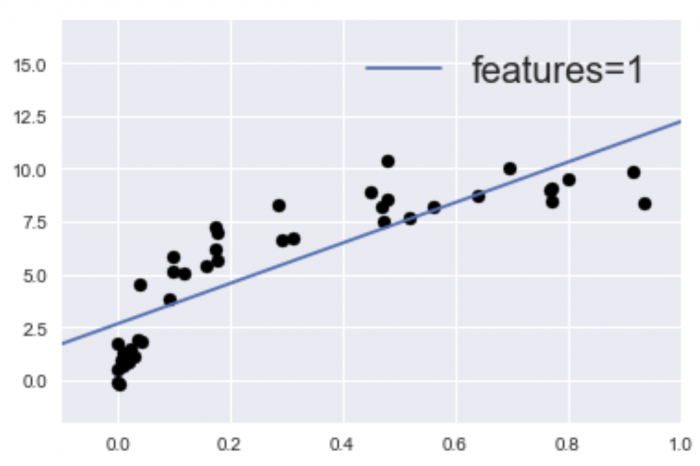
学習不足への対策は次の記事で紹介しています!

「ハイバイアス」についてもっと詳しく知りたい方はこちら

まとめ
つまり、「学習不足(未学習、underfitting)」とは
<参考>
AI(人工知能)って「なにそれ美味しいの?」ってレベルだった僕が、AIエンジニアを目指してステップを踏んだり踏まれたりしている記事を書いてます。よかったら読んでみてください(実話)。



コメントをどうぞ