
深層学習で時系列データを扱う際にLSTMが用いられることがありますよね。しかし実際にLSTMがどのような計算を行っているのかといった部分を深く理解はできていないことが多い人も多いかもしれません。本記事ではそのLSTMについてどのような計算を行い、どんな特徴を持つのかについて解説していきましょう。
LSTMとは
LSTMとはLong Short-Term Memoryのことで、ニューラルネットワークで用いられる層の1種で、LSTM自体は深層学習が流行するより以前から存在する手法で、原著論文は1997年に提案されています。
LSTMの提案論文:LONG SHORT-TERM MEMORY
LSTMは時系列を考慮する層であるRNN(リカレントニューラルネットワーク)を改良したもので、従来のRNNの問題であった勾配消失問題を解消し、より長期の時系列を考慮できるようになりました。
時系列を考慮できることから自然言語処理や時系列データの予測などに主に用いられます。
勾配消失問題
そもそも勾配消失問題とは何でしょうか。勾配消失問題とは、誤差逆伝播を行う際に何層にもわたって小さな値の乗算を繰り返し、次第に勾配の値がほぼ0となってしまい、学習がうまく進まなくなる問題のことです。また同様に何層にもわたって大きな値の乗算を繰り返し、勾配の値が大きくなりすぎてしまう問題を勾配爆発問題と呼び、こちらもうまく学習を行うことができません。RNNではこの勾配消失問題が生じることで、大きすぎる系列を考慮する場合に学習がうまく進まなくなるという問題がありました。
RNNとLSTM
本章ではRNNのアルゴリズムを解説し、その後LSTMではどのような変化が加えられて勾配消失問題の解消につながったのかについて説明します。
RNN
シンプルなRNNの概要図を以下に用意しました。
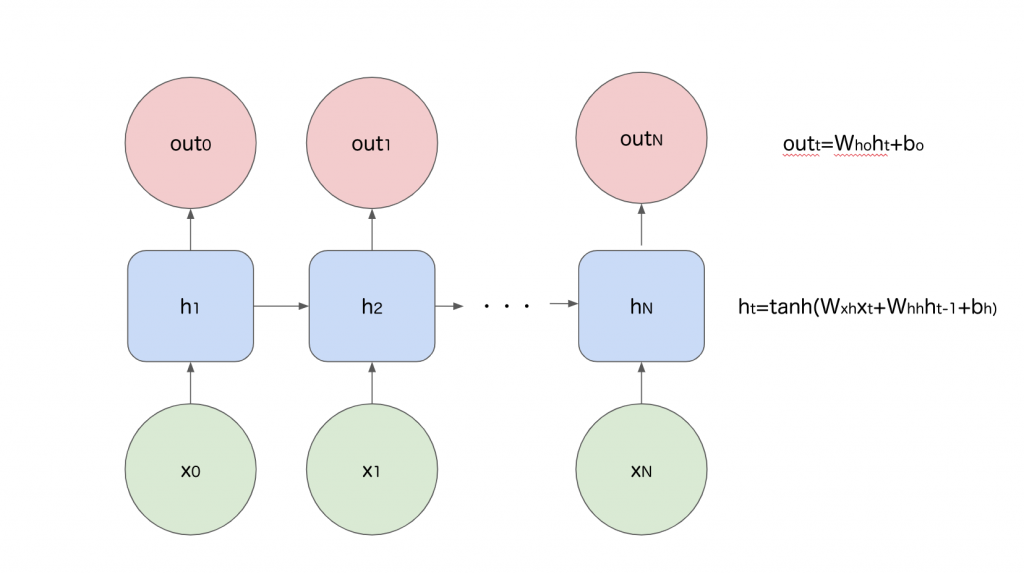
ある系列での入力x_tに対してh_tという状態を保持し、その状態を次の系列の入力に含めることで理論上は任意の系列を考慮することが可能な機構を保持しているのがRNNです。内部の計算自体は通常の全結合層で行われるような線形変換を複数回行い、その中でh_tを求める際に1回tanhを計算するだけの単純な仕組みですね。
RNNではh_tを計算するtanhの勾配の値が0から1の値となるため、層を重ねすぎた場合に勾配の値が小さくなりすぎ、勾配消失問題を引き起こします。そのためRNNによる計算を重ねすぎると学習がうまく進まなくなる問題があります。
LSTM
LSTMの層の仕組みを以下の図で表しました。*と+は要素毎の計算です。
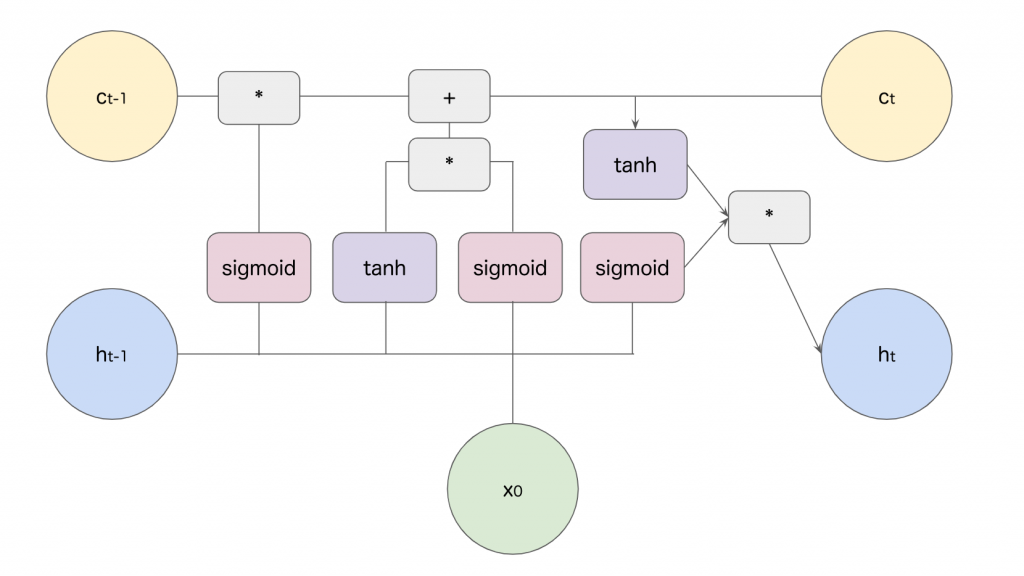
LSTMでは3つのゲートを利用して学習を行います。入力ゲート、出力ゲート、忘却ゲートから構成され、それらのゲートはsigmoid関数を通すことによって値が0から1の間に納められ、各ゲートは通る情報をどれだけ次に伝えるかを制御します。入力ゲートが入力値をどれだけ取り込むか、出力ゲートが次の時刻にどれだけ情報を伝えるか、忘却ゲートがセルに保持する情報をどれだけ伝えるかを制御します。
またConstant Error Carousel(CEC)と呼ばれるメモリセルを導入しています。セルは新たに記憶するべき情報を保持する仕組みで、この計算が各ステップで要素積と要素の和をとる計算だけであり、これによって勾配消失が起こりにくい仕組みとなっているんですね。
最近のLSTM
自然言語処理の分野でLSTMは広く利用されていましたが、2017年に登場したTransformer(トランスフォーマー)によってその影がだんだん薄くなってきているといえるでしょう。
Transformerは従来のRNNベースの手法ではなく、Attention(アテンション)によって時系列を考慮するような仕組みを持ち、RNN系の層と比較して計算効率が高く、また精度も高いという特徴があります。そのためそれ以降の自然言語処理系のモデルはほとんどがAttentionベースの手法を採用しており、LSTMを利用するモデルが減少しています。
またこのAttentionは自然言語処理に限らずテーブル形式のデータでも時系列を考慮する際に高い性能を誇り、従来LSTMが利用されてきた分野を置き換えつつあります。
まとめ
LSTMについて重要な点をまとめましょう。
- LSTMは系列を考慮するRNNに改良を加えたもの
- ゲートとセルの導入により勾配消失問題を解決し、より広い時系列を考慮できるようになった
- 現在はAttentionの台頭によって影が薄くなっている


