
最近はAI(人工知能)による画像生成がニュースとして取り上げられることも多くなりましたよね。 近頃のニュースでは、こちらなどが有名でしょう。
本記事では2015年末に発表された DCGAN(ディーシーガン)というアルゴリズムに関してご紹介します。現在は生成する画像の高解像度化や、学習の安定性向上などの研究がさらに進んでいますが、ここでは基礎に立ち返って、単純な畳み込みニューラルネットワーク(Convolutional Neural Network; CNN)を用いた画像生成を行っている DCGANを理解しましょう。
DCGANとは
DCGANとは Deep Convolutional Generative Adversarial Networks の略称で、2014年に発表されたGAN(Generative Adversarial Networks)を元に改善が加えられたアルゴリズムです。

https://arxiv.org/pdf/1406.2661.pdf より
- CNN の導入
- CNNのプーリング層をストライド付きの畳み込み層に変更
- Generator と Discriminator の両方に Batch Normalization を導入した
- Generator では活性化関数に ReLU を使用し、出力層のみ Tanh を使用
- Discriminator では活性化関数に LeakyReLU を全層に渡って使用
GAN(敵対的生成ネットワーク) とは
GAN(敵対的生成ネットワーク)は2014年に Ian Godfellow によって発表された生成モデルで、ニューラルネットワークを用いてノイズから様々な画像を生成することに成功しました。
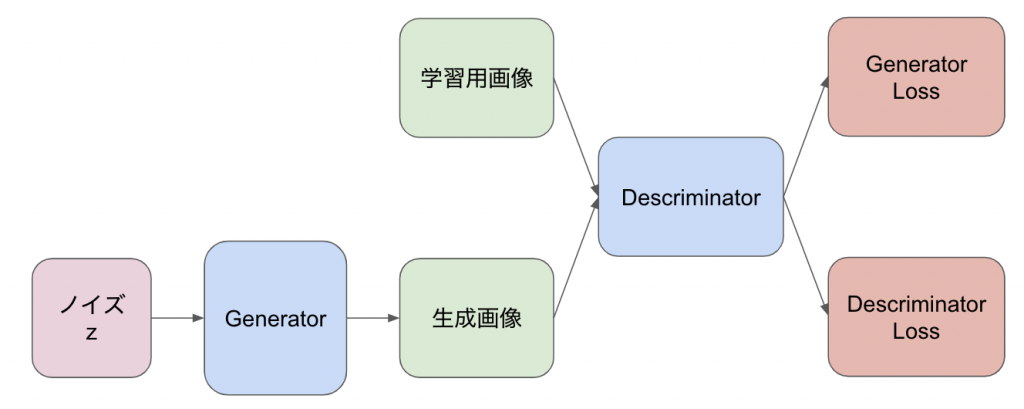
GAN(敵対的生成ネットワーク)の特徴は2つのネットワークが競い合うように(adversarialに)学習が進むことから命名されています。2つのネットワークはそれぞれ Generator、 Descriminator と呼ばれ、 Generator が生成した画像と本物の画像を、 Descriminator が本物か Generator が生成した画像かを見分けることで学習を進めます。
イメージしやすいように画像を用意しました。以下の画像のような構造で学習を行います。学習が進むにつれて Generator はより本物らしい画像を生成できるようになり、 Descriminator は生成画像を見分ける能力が上がっていきます。ここから競い合うようにという表現が生まれているんですね。
GAN(敵対的生成ネットワーク)の学習の難しさ
先ほどの説明の通り、 GAN(敵対的生成ネットワーク) は2つのネットワークが競い合うように学習を進めますが、この際 Generator が先に強くなりすぎると Discriminator がうまく生成された画像かを識別できず、競い合うことすら出来なくなってしまいます。逆も然りで Discriminator が先に強くなりすぎると、 Generator がどんな画像を生成しても全て生成画像であると見抜かれてしまい、本物らしさを学習できなくなってしまいます。
このような問題があるために DCGAN では学習を安定させるべく、様々な変更が加えられているのです。
DCGANによる生成画像
論文中ではいくつかの生成画像の例が記載されています。以下はベッドルームの画像を学習させ、DCGANにより生成した画像です。

https://arxiv.org/pdf/1511.06434.pdf より
人間が見てベッドルームだと自然に判断できる画像が多いですよね。また解像度の面では問題が残るものの、ベッドルームの特徴をかなり適切に掴めているように見受けられます。
また以下の画像は Generator の入力となるノイズの値を徐々に変えていった場合の生成画像です。
左端の人物を生成するノイズ、右端の人物を生成するノイズ、それぞれのノイズの値をどちらかに近づけていくと、2つの顔が混ざったような画像が生成されるという様子を表しています。

https://arxiv.org/pdf/1511.06434.pdf より
まとめ
DCGANについて重要な点をまとめます。
- 2015年に発表されたGAN(敵対的生成ネットワーク)の改良系モデルがDCGAN
- CNNを用いることでGAN(敵対的生成ネットワーク)の学習を安定させた
- 現在はこれを元にさらにGAN(敵対的生成ネットワーク)の高解像度化や学習の安定性向上への研究が進んでいる


