
機械学習に関する勉強を進めていると、交差検証(クロスバリデーション)という汎化性能を評価する手法が出てきます。汎化性能とは、未知のデータへのモデルの対応能力のことです。
※モデル:データのパターンや傾向を数式で表現したもの
交差検証は非常に重要な手法ですが、コード一行で終わってしまうため、内容をはっきりと理解しないまま使ってしまう場合があるかもしれません。そこで今回は、交差検証(クロスバリデーション)についてお伝えします。
一言で言うと「交差検証(クロスバリデーション)」とは・・・
交差検証を用いることで全データが1度だけテストに用いられる
機械学習のモデルが本当に実用的かどうかを検証する方法の一つに、「交差検証(クロスバリデーション)」があります。交差検証ではデータの分割を何度も繰り返して行って複数のモデルを訓練し、一般に最後は複数のモデルの平均値をとって最終的な性能とします。
中でも一番よく使われる交差検証手法は、K分割交差検証(k-fold cross-validation)で、10分割交差検証を行う場合の流れは次のようになっています。
※Kは人が定めます。
例えば開発データを10分割して、「9割の訓練セット」、「1割をテストセット」とする
※訓練セット:訓練データの集まり
※テストセット:テストデータの集まり
↓
「訓練セット」でモデルの学習を行う
↓
「テストセット」でモデルの性能を評価する。
↓
このプロセスを10回繰り返して性能の平均をとる。
少しややこしいのでまとめると、10分割交差検証はこんなイメージ。
※画像長いので注意です
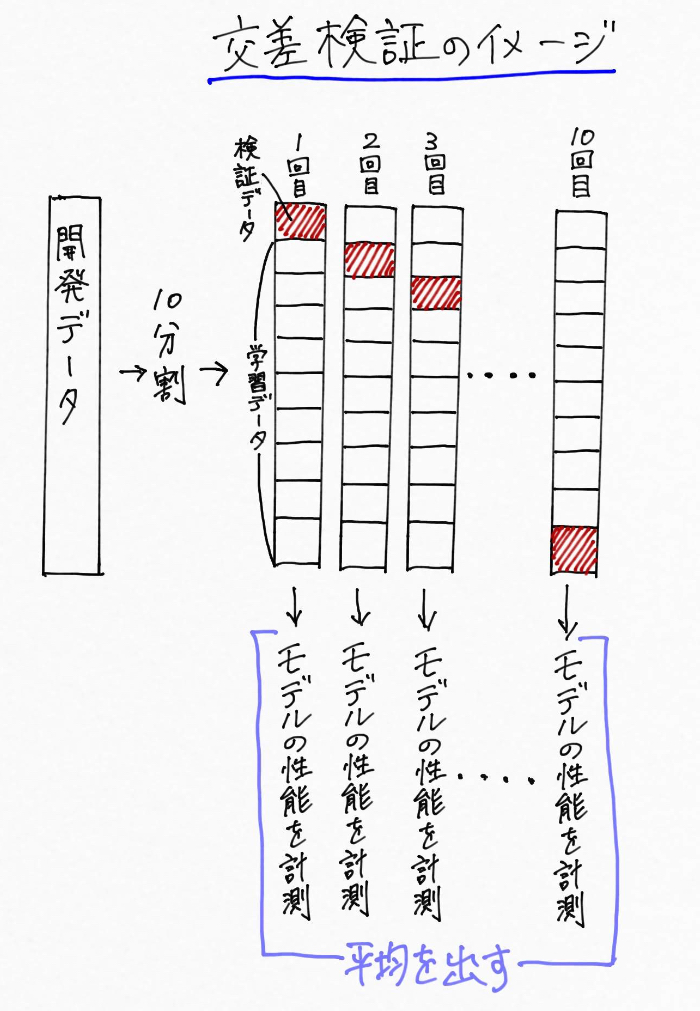
このような処理をする交差検証を用いることで、モデルの性能が偶然による影響を受けないようにすることができます。
例えば、犬の名前を教えてくれるAI(機械学習)を実装しようとしていて、「訓練セット」にはクラス(分類対象のカテゴリ)分類が難しそうな雑種犬の画像ばかりが入り、「テストセット」には分類がしやすい特徴がはっきりした犬の画像ばかりが入っていたら、、、モデルの精度はめちゃめちゃ高くなります。なぜなら解く問題(テストデータ)が簡単だからです。
逆に、クラス分類が難しそうな雑種犬の画像が全てテストデータに入っていれば、モデルの精度はめちゃくちゃ低くなってしまうでしょう。
その点、交差検証を使えば全ての犬の画像が必ず一度はテストデータとして利用されます。つまり、交差検証によって平均的に良い性能結果を出すモデルは、全てのデータに対して良い汎化性能を示すことになる!というわけです。
様々な交差検証の種類については以下でまとめています。興味のある方はこちらもどうぞ。

まとめ
つまり、交差検証とは
<参考>
・Andreas C. Muller and Sarah Guido (2016). Introduction to Machine Learning with Python: A Guide for Data Scientists. O’Reilly Media, Inc. (アンドレアス・C・ミューラー、サラ・グイド 中田 秀基(訳)(2017). Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎 株式会社オライリー・ジャパン)
・Sebastian Raschka(2015). Python Machine Learning. Packt Publishing. (株式会社クイープ、福島真太朗(訳)) (2016). 『Python機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)』
AI(人工知能)って「なにそれ美味しいの?」ってレベルだった僕が、AIエンジニアを目指してステップを踏んだり踏まれたりしている記事を書いてます。よかったら読んでみてください(実話)。



コメントをどうぞ