
Deep Learning(ディープラーニング)は、AI(人工知能)の近年の急速な発展を支える主要技術であり、その進歩により画像解析や音声認識、文書解析など様々な分野への実用化が進んでいますよね。GPUの発展などを背景に、PCの処理能力が高まっていることがDeep Learning実用化を後押ししていることをご存知の方もいらっしゃるかもしれません。
ディープラーニング、機械学習についてさらに知りたい方はこちら

カナダ・トロント大学のジェフェリー・ヒントン教授がDeep Learningの概念を論文で提唱したのは2006年ですが、Deep Learningが世の中の注目を大きく集めたのは2012年の以下の2つの出来事によるものです。
- 画像認識技術を競う世界的な競技会「ILSVRC」において、Deep Learningを使用したジェフェリー・ヒントン教授率いるチームが圧勝します。本競技会では毎年1%レベルの改善で進んでいたのをDeep Learningを利用したことにより、一気に約10%の改善を実現します。
- Googleとスタンフォード大学がDeep Learningにより猫の画像を「猫」と認識することに成功します。
その後、2016年にはDeep Learning技術によるディープマインド社の「AlphaGo(アルファ碁)」が韓国の囲碁棋士イセドル九段に勝利などの様々な業績を達成します。現在、Deep Learningは機械学習において最も成果を出している手法なんです。
Deep Learningは今後、様々なシステム開発における基盤技術となる可能性があり、今後はGPUの進化などを始めとしてPCの処理速度の高まりを受けながら、Deep Learning開発環境が広く世の中に浸透してゆくことでしょう。
このように、現在大変な注目を集めているDeep Learningですが、その仕組みやGPUがなぜPCの処理速度を上げることになるのか、そうしたことについては中々知らないものですよね。そこで今回は、Deep Learningの基本とCPの処理速度を向上させるGPUについてお伝えしていきましょう。
Deep Learningは脳の神経ネットワークを単純化してコンピュータのプログラム上で再現したもの

ここではDeep Learningの仕組みを大雑把に説明していきますが、Deep Learningには人間の脳の構造が深く関わっています。人間の脳は300億を超える(数については諸説あり)多数のニューロン(神経細胞)で構成されていると言われており、無数のニューロンとニューロンは、シナプス結合と呼ばれるつながりを作ることでネットワークを形成しているのです。
そしてDeep Learningは、ニューラルネットワークというコンピュータアルゴリズムに基づいて作られています。ニューラルネットワークとは、このような私たちの脳の仕組みを真似たもので、私たちの脳を構成しているニューロンが互いにつながって情報のやり取りしている仕組みをコンピュータ上に採用して再現したものです。
ニューラルネットワークの基本的な模式図は、下記のようなイメージです。
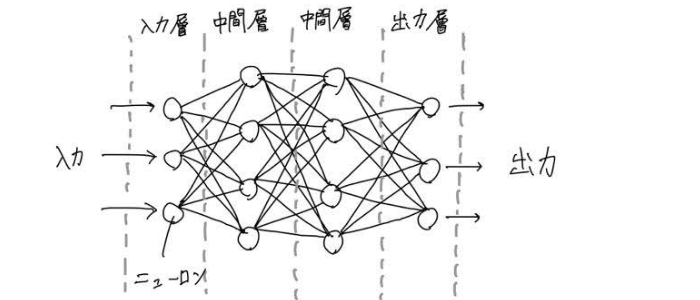
情報を受け取った一番左側のニューロン(入力層)は、情報を自分なりに処理をして、その結果を別のニューロンや次の層(中間層)のニューロンに伝達します。
情報を受け取った別のニューロンは自分なりの処理を行なった上で、また別のニューロンに情報を伝達します。情報は次の層へと受け継がれ、やがて一番右側のニューロン(出力層)にその結果を伝達し、出力層のニューロンが処理した結果を出力します。
これがニューラルネットワークの基本的な仕組みで、この例の中間層を増やして層を深くしたのがDeep Learning(深層学習)です(一般的に模式図に比べて層の数は増え、ニューロンは膨大な数に及びます)。
左の列から届いた情報について評価した結果を右の列に伝えるだけで、何の意味があるのかと思われるかもしれませんが、このように複数の層に渡る情報伝達を繰り返すことにより、コンピュータが「学習」できる(例えば犬の画像を犬と認識できるようになる)ことが分かっています。
さらに詳しく言えば、囲碁AI(人工知能)の場合、「碁石の位置や周囲の局面を数値で表現したもの」を入力層のニューロンはデータとして受け取り、これらを評価し、結果を右側のニューロンに送ります。次のニューロンには左側の多数のニューロンより数値情報が届き受け取ったそれぞれの情報に対しニューロンは評価を行い、結果を右側のニューロンに送ります。
こういった処理を全てのニューロンが行った結果、良くない結果となってしまった場合には学習した情報に対して修正が行われます。このプロセスを繰り返すことによって、より強くなってゆきます。
以上、かなり長い説明となってしまいましたが、まとめますと、Deep Learningではニューラルネットワークを構成するニューロンがやっていることをものすごく簡単に言うと、左の列より送られてきた多数の情報に対し、評価した結果を右の列に伝える、という繰り返しをすることです。
※ニューラルネットワークについては以下のページで簡単に解説しています
次に、このニューロンの模式図で示してきたことをコンピュータ上でどう実行しているのか、について見てみましょう。
ニューロンたちがやっていることをコンピュータ上でどう実行しているのか

模式図を例に解説したように、ニューラルネットワークにおけるニューロンで行われていることは、左の列のニューロンより送られてきた情報を評価し、その結果を右の列のニューロンたちに伝えることでしたよね。
Deep Learningは、PCなどのコンピュータで行われる演算処理です。ニューラルネットワークを構成する層の数が増えた場合、多数のニューロンが列方向と行方向の両方に並んでいる形を踏まえて、ニューロンで行われていることを数式で記述すると「行列の演算処理」と表現できます。(左の列のニューロンたちより送られてきた数値に対して数値演算処理を行う、という処理が行列の演算処理として記述されます)
つまり、Deep Learningでは極めて大量の行列の演算処理が必要となるのです。例えば、先程ご紹介したGoogleによる猫画像の認識においては1,000台のコンピュータで3日間かかったと言われています。
(参考:この3日間はDeep Learningによる学習に要した時間ですが、その前にはGoogle研究者による人間として設定すべきパラメータ調整に関する、長い試行錯誤の時間なども別途必要となります)
Deep LearningをPCで実行する場合には欠かせないGPU

大量の行列の演算処理が必要となるため、Deep LearningをPCで実行する場合に欠かせないのがGPUというハードウェアです。前述したように、GPUの発展がDeep Learningの実用化を後押ししています。GPUと似た言葉でCPUがありますので念のためここで整理しましょう。
- CPU(Central Processing Unit):コンピュータの制御や演算や情報転送をつかさどる中枢部分。中央処理装置。
- GPU(Graphics Processing Unit):リアルタイム画像処理に特化した演算装置ないしプロセッサ ※プロセッサ:コンピューターにおいて命令を解読、実行する装置のこと。コンピューターの中で最も重要な機能を果たします
CPUとGPUの大きな違いは同時に実行できる処理数の件数です。CPUでは一般的には4~16件の処理しか同時に実行できませんが、GPUだと数百~数千件の処理を同時に(並列して)行うことができます。
Deep Learningのように、PCで大量の行列の演算処理という、同じような処理を繰り返し行う必要がある場合にはCPUだと時間がかかりすぎてしまうため、処理時間を短縮するコンピュータの高速化にはGPUがとても有効だということがわかったのです。
先程のGoogleの猫の場合、Googleが使用した当時のコンピュータのCPUは同時に16件しか処理できなかったため、1,000台も準備する必要がありました。使用条件によって異なりますが、一般的にはDeep LearningをPCで実行した場合のGPU 効果はCPUの約数十倍から数百倍とも言われています。
(参考)GPUはもともとは、3Dゲームなどのリアルタイム画像処理に特化したハードウェアです。3D映像は(肉眼では判別できない)非常に小さな三角形の組み合わせで構成されており、この極めて大量の三角形の座標計算を3Dゲームソフト用途などのために高速に処理する必要があったため、GPUは多数の並行処理機能を持つ必要がありました。
まとめ
ということで、今回Deep Learningの基本とPCの処理速度を向上させるGPUについてお伝えしてきました。
- Deep Learningは脳の神経ネットワークを単純化してコンピュータのプログラム上で再現したもの
- Deep LearningはPCにおいて極めて大量の行列の演算処理を行う必要がある
- Deep LearningをPCで実行するためにはGPUは欠かせない
GPUは、リアルタイム画像処理に特化した演算装置であり、元々は画層処理用に開発されたハードウェアであって、Deep Learningのために開発されたものではありません。どちらかというと、AI(人工知能)研究者がDeep Learningにも使えると気がつき活用されているものです。
こういったこともあり、実はGPUにはDeep Learning用としては不要な機能も含まれており、Googleがその余分な機能を省いて高速化/省電力化を実現したプロセッサがTPU(Tensor Processing Unit)を開発しています。現在はまだ市販されていないようですが、今後Deep Learningがシステム開発における基盤技術として浸透すれば、Deep Learning専用ハードウェアとして私たちも安価に利用できる時代が来るでしょう。期待して待つことにしましょう!
参照元
第1部 特集 IoT・ビッグデータ・AI~ネットワークとデータが創造する新たな価値~
人工知能の歴史
”第1回
第2回 ディープラーニングのモデルと専用サーバーを知る
猫を認識できるGoogleの巨大頭脳
ディープラーニングとハードウェアを考察する
【図解】なぜGPUはディープラーニング・AI開発に向いているの?選び方は?NVIDIAさんに聞いてきました
ディープラーニングで大活躍のGPU!その理由と種類・開発環境まとめ
