
画像分類タスクといえば畳み込みニューラルネットワーク(以下CNN)が代表的なモデルとしてよく紹介されていますよね。実際CNNの活躍には目を見張るものがありますし、CNNを理解し使いこなせるようになれば一気にできることが広がります。
けれど勉強をしてみてもどう作れば良いのかわからない人は多いことでしょう。そこで、そんな人に向けてCNNについてお話しします。
チュートリアルの第1回は、CNNと画像分類の基本についてまとめてみました。この記事を読み終わった頃にはCNNに対する理解とさらに学びを深めていくためのモチベーションが一層高まっているはず。
本記事ではまずCNNとは何かと有名なCNNのモデルについて学習し、その後PyTorchの使い方を説明します。最後は実際にCNNを実装し画像分類を実行、という流れでCNNと画像分類にの基本についてお伝えしていきます。
- Python
- ニューラルネットワークに関する基礎的な知識
- 機械学習に関する基礎的な知識
畳み込みニューラルネットワーク(Convolutional Neural Network: CNN)とは

「CNN」とは、畳み込み層やプーリング層(ないことも多い)を中心に構成されるニューラルネットワークのことです。今回のチュートリアルでは画像を扱いますが、画像だけでなく自然言語、音声など様々なタスクで使用されるネットワークでもあります。
そして、「畳み込み層」とは、空間計算量・時間計算量ともに、全結合層と比較して非常に小さなコストで実行可能という利点があります。畳み込みは一般に学習するパラメータが少ないためメモリ効率が良く、また計算の並列化が容易なため高速に動作する特徴があります。
ResNetとは
「ResNet」とはMicrosoft Researchによって2015年に提案されたニューラルネットワークのモデルです。現在の性能の良いCNNとして提案されているモデルはほとんどこのResNetを改良したモデルなので、今回はその基礎となるResNetとは何かを知ることにします。
これは単純に総数を重ねることでは、逆伝播時に最初の方の層まで、学習に必要な十分な勾配が流れて来ないこと(勾配消失問題: gradient vanishing problem)が原因でした。
そして、ILSVRCという毎年開催されていたImageNetを用いた画像分類コンペにおいて、2014年以前はせいぜい20層程度(VGGが16か19層,GoogleNetが22層)のモデルで競っていたのに対し、ResNetは152もの層を重ねることに成功、ILSVCRの2015年の優勝モデルとなったのです。
shortcut connectionとは
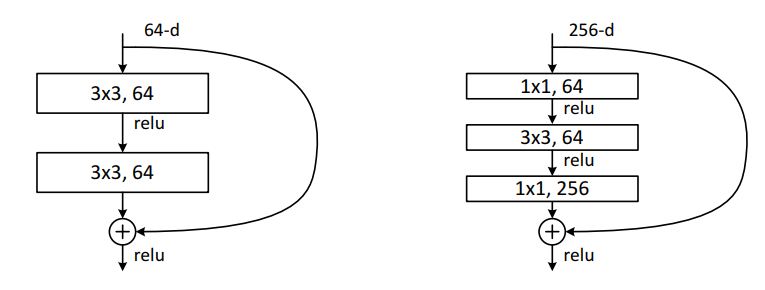 ResNetにおけるshortcut connectionは,上図の2通りあります。
ResNetにおけるshortcut connectionは,上図の2通りあります。
この図の通りいくつかの層を飛び越えて、手前の層の入力が足し合わされます。これにより逆伝播時に、勾配が直接的に手前の層にまで届くようになるので、効率よく学習が進みます。 またこの構造を数式で表現すると以下のように。
building blockへの入力を x 、building block内の層の出力を F(x) 、最終的なbuilding blockの出力を H(x) で表現しています。
H(x) = F(x) + x
これは手前の層で学習しきれなかった誤差の部分を次の層で学習することを表すので、機械学習のアンサンブル学習で用いられるstackingという手法と同じであると見なせ、精度の向上にも寄与しています。
Deep Residual Learning for Image Recognition
PyTorchによる簡単なCNNとResNetの実装
まずはPyTorchのモデルの構築になれるため、簡単なネットワークであるAlexNetを実装してみます。
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, in_channels, num_classes):
super(AlexNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=96,
kernel_size=11, stride=4)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv2 = nn.Conv2d(in_channels=96, out_channels=256,
kernel_size=5, stride=1, padding=2)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv_layers = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.fc_layers = nn.Sequential(
nn.Linear(in_features=9216, out_features=4096),
nn.Linear(in_features=4096, out_features=4096),
nn.Linear(in_features=4096, out_features=num_classes)
)
self.softmax = nn.Softmax(dim=0)
def forward(self, x):
x = self.maxpool1(self.conv1(x))
x = self.maxpool2(self.conv2(x))
x = self.conv_layers(x)
x = x.view(x.size(0), -1) # [B, C, H, W] -> [B, C*H*W]
x = self.fc_layers(x)
return self.softmax(x)
if __name__ == '__main__':
inputs = torch.zeros((16, 3, 227, 227))
model = AlexNet(in_channels=3, num_classes=10)
outputs = model(inputs) # [16, 3, 227, 227] -> [16, 10]
print(outputs.size())
PyTorchではtorch.nn.Moduleというクラスを継承する形でモデルを定義します。 そしてコンストラクタ内で親クラスを継承し、forwardメソッドを定義するだけでモデルを構築できます。またtorch.nn.Moduleを継承したクラスはここで用いられているtorch.nn.Linearやtorch.nn.Conv2dなどのように部品としても使用可能で、構造が複雑なモデルではいくつかの部品ずつ構築し、最後にそれをまとめてモデルのクラスを定義します。 torch.nn.Sequentialクラスは内部にtorch.nn.Moduleを複数個書くことで、それらをまとめてひとつのインスタンスにできるため、よく使用します。
torch.Tensorは比較的NumPyライクに作られてはいますが、x.viewでreshapeしたり、x.size()でshapeを取得したり(ndarrayではx.shape())、軸の指定がdimというパラメータになっているなど、少し挙動が異なるので注意が必要です。
PyTorchで画像を扱う場合のモデルの入力は、(Batch Size, Channel, Height, Width)となっており、Kerasなどとは異なるので注意。(Kerasは(B, H, W, C))
ResNetの実装
今回はResNet18を実装します。 まずはResNet18に用いるBasic Blockの実装が以下のコードです。
# kernel_sizeが3x3,padding=stride=1のconvは非常によく使用するので、関数で簡単に呼べるようにする
def conv3x3(in_channels, out_channels, stride=1, groups=1, dilation=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=True,
dilation=dilation)
def conv1x1(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=True)
class BasicBlock(nn.Module):
# Implementation of Basic Building Block
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
identity_x = x # hold input for shortcut connection
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity_x = self.downsample(x)
out += identity_x # shortcut connection
return self.relu(out)
これらをまとめてひとつのモジュールにします。
class ResidualLayer(nn.Module):
def __init__(self, num_blocks, in_channels, out_channels, block=BasicBlock):
super(ResidualLayer, self).__init__()
downsample = None
if in_channels != out_channels:
downsample = nn.Sequential(
conv1x1(in_channels, out_channels),
nn.BatchNorm2d(out_channels)
)
self.first_block = block(in_channels, out_channels, downsample=downsample)
self.blocks = nn.ModuleList(block(out_channels, out_channels) for _ in range(num_blocks))
def forward(self, x):
out = self.first_block(x)
for block in self.blocks:
out = block(out)
return out
そしてResNet18の全容がこちら。
import torch
import torch.nn as nn
from . import layers
class ResNet18(nn.Module):
def __init__(self, num_classes):
super(ResNet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = layers.ResidualLayer(2, in_channels=64, out_channels=64)
self.layer2 = layers.ResidualLayer(2, in_channels=64, out_channels=128)
self.layer3 = layers.ResidualLayer(
2, in_channels=128, out_channels=256)
self.layer4 = layers.ResidualLayer(
2, in_channels=256, out_channels=512)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
if __name__ == '__main__':
inputs = torch.zeros((16, 3, 227, 227))
model = ResNet18(num_classes=10)
outputs = model(inputs) # [16, 3, 227, 227] -> [16, 10]
print(outputs.size()) # [16, 3, 224, 224] -> [16, 10]
ResNetを用いた画像認識
今回はtorchvisionに用意されているCIFAR10というデータセットを用います。
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
import config
from resnet import ResNet18
class Trainer:
def __init__(self, model, optimizer, criterion):
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.model = model.to(self.device)
self.optimizer = optimizer
self.criterion = criterion
def epoch_train(self, train_loader):
self.model.train()
epoch_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs = inputs.to(self.device)
targets = targets.to(self.device).long()
self.optimizer.zero_grad()
outputs = self.model(inputs)
loss = self.criterion(outputs, targets)
loss.backward()
self.optimizer.step()
epoch_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum().item()
epoch_loss /= len(train_loader)
acc = 100 * correct / total
return epoch_loss, acc
def epoch_valid(self, valid_loader):
self.model.eval()
epoch_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(valid_loader):
inputs = inputs.to(self.device)
targets = targets.to(self.device).long()
outputs = self.model(inputs)
loss = self.criterion(outputs, targets)
epoch_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum().item()
epoch_loss /= len(valid_loader)
acc = 100 * correct / total
return epoch_loss, acc
@property
def params(self):
return self.model.state_dict()
if __name__ == '__main__':
model = ResNet18(10)
optimizer = torch.optim.SGD(model.parameters(),
lr=0.001,
momentum=0.9,
weight_decay=1e-4)
criterion = nn.CrossEntropyLoss()
trainer = Trainer(model, optimizer, criterion)
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
dtrain = torchvision.datasets.CIFAR10(
'./data/', train=True, transform=transform, download=True)
dvalid = torchvision.datasets.CIFAR10(
'./data/', train=False, transform=transform, download=True)
train_loader = DataLoader(dtrain, batch_size=config.BATCH_SIZE, shuffle=True,
drop_last=True)
valid_loader = DataLoader(dvalid, batch_size=config.BATCH_SIZE)
best_acc = -1
for epoch in range(1, 1 + config.NUM_EPOCHS):
train_loss, train_acc = trainer.epoch_train(train_loader)
valid_loss, valid_acc = trainer.epoch_valid(valid_loader)
if valid_acc > best_acc:
best_acc = valid_acc
best_params = trainer.params
print(f'EPOCH: {epoch} / {num_epochs}')
print(f'TRAIN LOSS: {train_loss:.3f}, TRAIN ACC: {train_acc:.3f}')
print(f'VALID LOSS: {valid_loss:.3f}, VALID ACC: {valid_acc:.3f}')
torch.save(best_params, 'weight.pth')

さて、今回のチュートリアル第1回は画像分類とCNNについて学習してきました。
まず、CNNの概要から始まって、有名なモデルの一つであるResNetの実装方法を確認し、実際に画像分類を実行しました。
現在、画像分類は、工場での異常検知や医療画像の診断など様々なシチュエーションで使用されています。また、今開発中の自動運転にもこの画像分類をもとにした技術が使用されていたりと汎用性の高いタスクでもあります。ですから今このCNNについて学んでおいて決して損はありません。
今回ご紹介したチュートリアルでぜひCNNを学んでください。そして、この記事に記載したコードを実行しながらCNNの基本を押さえることで、引き続き画像分類についての理解を深めていきましょう。


コメントをどうぞ
この実装だと、num_blocks=2で、さらにfirst_blockがあって、各Layerのblock数が3になってしまいません?